- January 4, 2022
- Posted by: admin
- Category: Data Science
Text Analytics, also known as Text Mining, is a technique used to derive insights from text data. The field has picked up some traction in review and customer analysis, and provides businesses with deeper insights regarding their customers. Everyone who has used an e-commerce site understands how consumer reviews, or lack thereof, can have a direct impact on new consumers, and thus, the business.
An understanding of basic concepts and techniques used in text mining can help an analyst better understand text data, and derive useful information from a source where others just see “words”. Similarly, it can help an organization better understand the consumer’s view of the organization, and thus help in their decision making, to drive growth.
About 6 months ago, armed with the knowledge of Python, Andrew Ng’s Machine Learning Course[1] , and some exposure to Machine Learning challenges on Kaggle, I decided to try my hands on Text Analytics. As I ventured through various google searches and online forums, I learnt about the bag of words models, normalizing text by case, and the most famous word in the world of text analytics – Word clouds. In the process, I learnt how to parse text data from online sources using python, and programming in R, because a lot of forums talked about various packages (“tm”, “corelearn”, etc) available for the language which make text analytics easier to do.
By the end of month 3, I felt I had enough knowledge to analyze text data, but lacked the confidence to apply what I had learnt, partly because I felt that a lot of monotonous work, such as normalizing by case, removing stopwords, creating a vector space representation from the text data, etc, goes into coding for text analytics. It took me another month to apply everything I had learnt and derive useful insights from a moderately sized dataset. That is when I stumbled upon Analyttica Treasure Hunt. It is a patented training and knowledge immersion platform by Analyttica Data Lab. The platform has 500+ prebuilt R functions integrated into it, which can be utilized for various kind of analysis. The point and click interactive interface of the platform will help us to focus on the real analysis, rather than the nitty-gritty of programming.
This blog discusses text mining techniques, from frequency analysis to K-Means clustering, on a complaints dataset (CFPB), to understand the consumer demographics, and the underlying themes in the dataset, if any.
To reiterate, Text Analytics is a time-consuming process. Hence, some of you might feel that this blog goes on forever. To those analysts, here’s a six minutes long video which shows all the steps I have covered in this blog. You can also try out your own analysis on this dataset, or look at the steps covered in this blog on How To Leverage Text Analytics. You can also join our Text Analytics Webinar with Satyabrata Samanta, VP – Client Solutions, Analyttica Datalab Inc. and Tathagata Mukhopadhyay, AVP – Client Solutions, Analyttica Datalab Inc.
https://learn.analyttica.com/learn/How To Leverage Text Analytics
About the Dataset:
The Consumer Financial Protection Bureau (CFPB) is a U.S Government agency, responsible for consumer protection in the financial sector. CFPB jurisdiction includes banks, credit unions, securities firms, payday lenders, mortgage-servicing operations, foreclosure relief services, debt collectors and other financial companies operating in the United States.
Among the various roles that CFPB plays, it monitors and tracks consumer complaints against multiple institutions. This is the data we explore in this discussion. The dataset consists of 5000 rows of consumer complaints across various products and companies.
The dataset can be downloaded from the CFPB website. The one used in this discussion is a random sample of 5000 rows from a larger dataset.
Let’s start the analysis by looking at the data.

We can see that the dataset contains columns which tell us about the Product, Sub-Product, Issue, etc., that the complaint belongs to. Most of these variables look to be categorical, i.e., we could use these to further filter the data in situations where we would like to analyze the complaints for a particular Product, Issue , etc.
Understanding the data
Though manually looking at the data is a good practice to get a basic understanding of the data, when the number of columns increases, it becomes cumbersome. Another disadvantage of manually exploring the data is that we might not get enough information regarding the data-types. To understand the data better, let’s summarize the data.

The data summary is clearly more informative than just looking at the data. From the summary, we can make some quick conclusions as follows:
- i) The dataset contains a total of 5000 observations for 18 variables.
- ii) Product variable is a categorical variable with 17 unique categories.
- iii) Issue variable is a categorical variable with 130 unique categories.
- iv) Consumer_complaint_narrative is a variable with 4994 unique categories. This indicates that the variable is unique for almost all the rows.
- v) The dataset contains complaints regarding 742 Companies.
- vi) The dataset contains complaints from 55 unique States.
- Where are the complaints coming from?
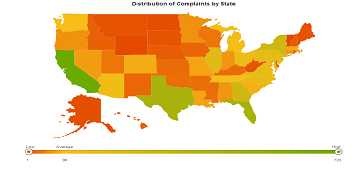
From the data summary, it is seen that there are 55 unique states with 23 missing values. The missing values are all clubbed into a single category, hence making it 54 unique states with the 55th category comprising of all the missing values. To examine how the complaints are distributed across various states, we can plot them on the map of USA and visually examine the distribution.

Figure 3: Map Plot Showing Distribution of Complains We can see that the distribution is highly skewed to the right, with a low of 1, average of 50, and a high of 729. Looks like most of the complaints are coming from a few green colored regions.
Figure 4: States with High Number of Complains The complaints are distributed as such:
- – California – 729
- – Florida – 462
- – Texas – 454
- – Georgia – 286
- – New York – 277
- .
- .
- .
- – Minnesota – 54
It might make sense to conclude that most of the complainants reside in these 4-5 regions, but a quick look at Wikipedia’s “List of U.S. states and territories by population[4]” shows us that these are just the most populated areas in US. Looking at the distribution relative to total population of the area paints a slightly different picture.
- – California – 0.0018%
- – Florida – 0.0022%
- – Texas – 0.0016%
- – Georgia – 0.0027%
- – New York – 0.0013%
- .
- .
- .
- – Minnesota – 0.0009 %
Which Products do people complain about? As we noted earlier, Products is a categorical variable, and can be used to further filter the data. Since it is a categorical variable with 17 values, we can visualize the distribution of complaints by products, using a pie chart as such,
Figure 5: Distribution of Complains by Products We can note that most of the complaints (59.4%) belong to just 3 categories –
- – Debt Collection – 23.4%
- – Mortgage – 19.04%
- – Credit Reporting – 16.96%
Add to that the category of “Credit card” (9.58%), and we can conclude that about 70% of the data focuses on 3 broad categories – Credit Cards, Debt Collection, and Mortgages. Another thing to note is that the “Students Loan” category falls 6th in the list.
Which companies do people complain about? Just like the products, another interesting categorical variable is “Company”, which has 742 unique categories. Let’s look at the distribution of complaints by Company.
Figure 6: Distribution of Complains by Company We see that there are a few companies that are talked about more than the others. Of these, the tallest bar belongs to Equifax Inc., with a value of 370. Equifax is a consumer credit reporting agency, that collects and aggregates information of individuals, as well as businesses. This information is in coherence with our earlier distribution charts, where most of the complaints (~25%) were pertaining to credit cards.
Other prominent bars in the distribution belong to Experian Information Inc. (319), Transunion Intermediate Holdings (318), Bank of America, National Association (325), and Wells Fargo & Company (327).
What do the complaints talk about?
The crux of the data is formed by the “Consumer_complaint_narrative”, which is raw unstructured text describing the issue faced by the consumer, as seen upon exploring the data.
Figure 7: Sample Complains To get a quick understanding of the theme of the complaints, we can plot a wordcloud of the text data.
Figure 8: Word Cloud As noted in the previous frequency analysis, most of the complaints talk about “credit” and “account”. This doesn’t add much information to the analysis. Hence, we plot another word cloud, this time omitting the words credit, and account from the analysis.
Figure 9: Revised Word Cloud This wordcloud gives us slightly more insight into the complaints. Apart from credit and account, people complain about “payment”, “loan”, “bank”, “information” (or lack thereof), report (credit, Equifax), etc. To get a deeper understanding of the complaints, we plot word clouds for each class of product.
Figure 10: Word Clouds by Product We note that most categories conform to their respective wordclouds. One important observation is the “Money Transfers” category, where people seemingly complain a lot about “Paypal”.
Do the complaints belong to certain themes?
Another interesting technique that can lead to new insights is clustering. Clustering helps in identifying themes that might not be apparent from a simple frequency analysis. Let’s split the “Consumer_complaint_narrative” into 5 categories (using K-Means Clustering), and then plot their respective word clouds.
Figure 11: Word Clouds by Segments We note that each cluster captures one specific theme from the data i.e., Account, Debt, Loan, Credit, and Credit-Report. From the last two word clouds, we can also conclude that the two represent a similar theme, and hence, can be clubbed into one.
Which sentiments do the complaints convey?
The data is about complaints from consumers, regarding companies. But how sad are the consumers about their issue. Using a dictionary comparison approach, we rate the “Consumer_complaint_narrative” on a scale of -1(highly negative) to +1(highly positive).
An example of a highly negative data-point is
One of the neutral data-point is Figure 12: Sentiment Analysis Though the entire dataset is regarding consumer complaints, we see a fair chunk of neutral, and a few positive complaints. This indicates that in some complaints, the consumer is harsh and uses a direct approach, while in other cases, they are sarcastic, and or indirect regarding the complaint.
Conclusion
We started with the CFPB data with 5000 rows and 18 columns and carried out basic exploratory analysis on the dataset. We studied the distribution of complaints by region, company, product, etc. We also explored what the complaints looked like and the information stored in those complaints. We understood the underlying themes in the data, using visualization tools such as bar plots, pie charts, maps and wordclouds. In the end, we analyzed the sentiments in the complaint narratives and found out that while some complaints are direct and harsh, others are not.
I would share the code used for this entire project, but since I didn’t write any, there is no code available! As I already mentioned, the entire analysis was carried out using a point-and-click analysis tool called Analyttica TreasureHunt. The tool helps one analyze data and learn the core concepts of Data Analysis, without having to worry about the various statistical coding frameworks and languages out there.















 One of the neutral data-point is
One of the neutral data-point is 
