- January 4, 2022
- Posted by: admin
- Category: Data Science

Need for Explainable AI (XAI)
Explainable AI (XAI) refers to methods and techniques in the application of artificial intelligence technology such that the results of the solution can be understood by human experts.
The tradeoff between the accuracy of a model and it’s explainability has always existed, though with the rise in popularity of complex ‘Machine Learning’ models and techniques, this trade off has risen to the fore front. The complex ‘Machine Learning’ models are able to boost predictions, though their adoption has faced the hurdle of “Black-Box” implementation, where any insight on the workings of the model and especially the ability to explain predictions in a simplified format, have kept industry domains, especially the regulated ones like Financial Services and Healthcare, at bay, limiting their adoption to drive business impact.
In the given scenario, where businesses are looking to leverage every piece of arsenal from their data assets, to find competitive advantage and be future ready to ride through this uncertainty, there is a growing need to be able to find solutions that are driven by application of complex ML techniques and at the same time being able to apply them in a “White Box” approach, providing rationale behind those predictions, which will enable, bringing all business stakeholders at the same page.
Explainable AI not only helps the data scientist explain the model to the clients, business leads or the end users, however it also plays a key role in debugging a model. Being able to apply a ML model in a ‘White-Box’ approach, the Data Scientist can analyze the model at an atomic level and infer if the model is making the right predictions on the test data, though for the wrong reasons or if the model predictions are in line with the business domain and understanding. Such discrepancies in the model can be identified and fixed during the model development stage and with XAI, the analyst is better positioned to strengthen their model building process and boosting the reliability of their model.
XAI provides the tools and techniques to interpret predictions. LIME based XAI frameworks are one of the most popular techniques used, that work well with complex models.
What is LIME?

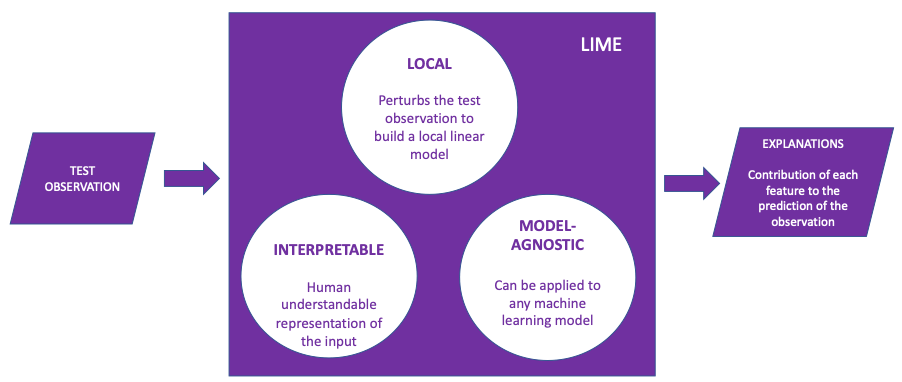
LIME stands for Local Interpretable Model-agnostic Explanations. It is a visualization technique that helps explain individual predictions. It is model agnostic so it can be applied to any supervised regression or classification model. LIME was presented by Marco Tulio Ribeiro, Sameer Singh and Carlos Guestrin in 2016.
Behind the workings of LIME lies the assumption that every complex model is linear on a local scale. LIME tries to fit a simple model around a single observation that will mimic how the global model behaves at that locality. The simple model can then be used to explain the predictions of the more complex model locally.
LIME supports three types of input formats, tabular data, text data and image data. In this paper, we will cover the interpretations made by LIME on tabular data, leveraging a solution that we had developed for one of our clients in our patented platform Analyttica TreasureHunt® Precision (details covered in the ‘Business Case Details’ section).
Explanation of the LIME Algorithm
- For the observation to be explained, perturb (unsettle or disturb) the observation n times to create replicated feature data with slight value modifications. This perturbed data is a fake data created around the observation to be used by LIME to build the local linear model.
- Predict outcome for the perturbed data
- Calculate the distance from each perturbed data point to the original observation
- Convert distance to similarity score
- From the perturbed data, select m features that best describe the predictions
- Fit a simple model to the perturbed data for the selected features
- Feature weights (coefficients) of the simple model are the explanations of the observation
Business Case Details
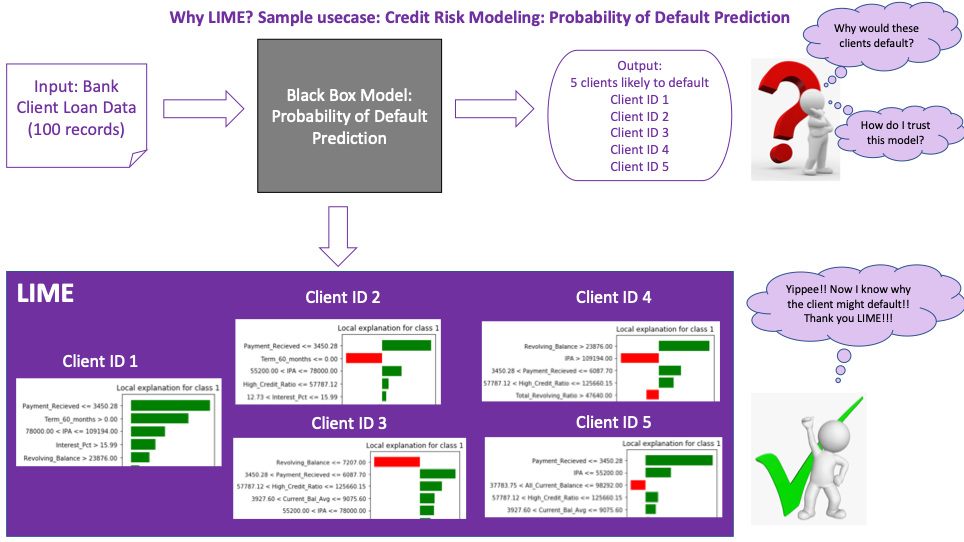
One of our clients, a US based mid-sized Credit Card issuer, wanted to develop a data driven strategy to avoid customers from defaulting and implement remedial measures for the payment schedule.
The objective here was to identify customers who are likely to default over the next 6 months, for which we developed a Risk Score to identify the risky customers and target them with remedial measures proactively.
As part of the complete Risk scoring framework, the following elements were delivered to the business –
1. Best model for predicting ‘Probability of Default’ of a customer over the next 6 months
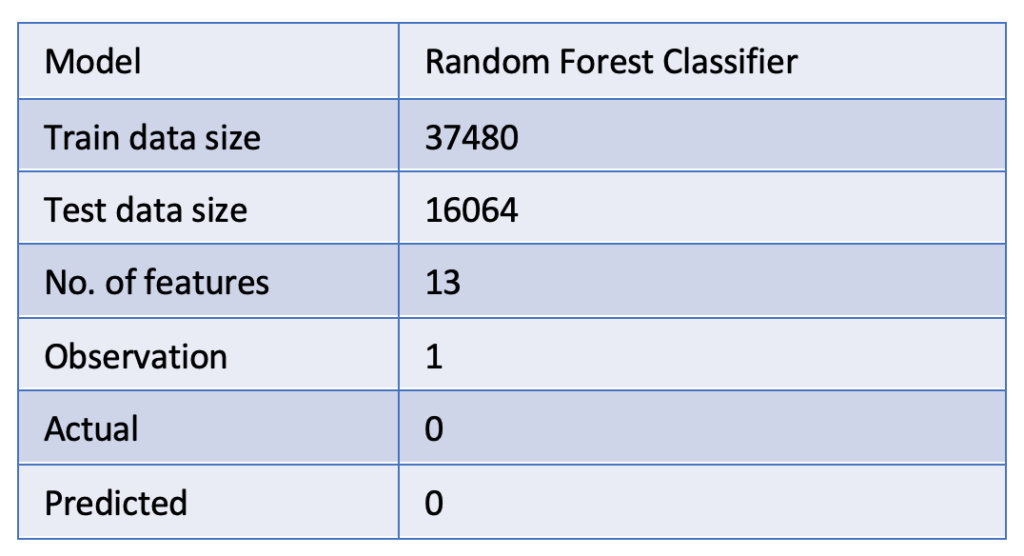
- We leveraged our patented platform Analyttica TreasureHunt® Precision Sandbox for rapid experimentation to test out 5 different algorithms for the prediction model
- ATH Auto ML feature was leveraged to compare the 5 models, and arrive at the final algorithm
- The classification algorithm was further tuned to increase prediction accuracy
2. Complete XAI framework, built on LIME and SHAP techniques, for interpretation of risk score at a customer level
The complete details of the business case starting from masked raw data, data treatment approach, feature selection methods applied, model comparison, hyperparameter tuning and explainable AI framework, was converted into a solution and has been made available as data cases on our ‘Open Platform’ Analyttica TreasureHunt® LEAPS, below are the links –
Reference Data-Case 1 – Data treatment & feature selection
https://leaps.analyttica.com/sample_cases/442
Reference Data-Case 2 – Model comparison & XAI
https://leaps.analyttica.com/sample_cases/443
Leveraging this business scenario, now we will focus on the interpretation and understanding of how LIME explains predictions. The first 10 lines of the perturbed data are shown in the below illustrations to get an understanding of how the data changes at every stage.
Decoding LIME
The way LIME handles categorical variables is different from how it handles the continuous variables. For categorical variables, the perturbed data will have binary values of 0 or 1. The value will be 1 if the perturbed entry is same as the observation to be explained, else it will be 0.
Both the cases are explained below in two different cases. In the first case, the continuous variables are discretized and in the second case they are not discretized.
Step 1: Creating the inputs required for the linear model
- Perturbing the data
- Discretizing the data
- Predicting on the perturbed data
- Calculating the similarity score
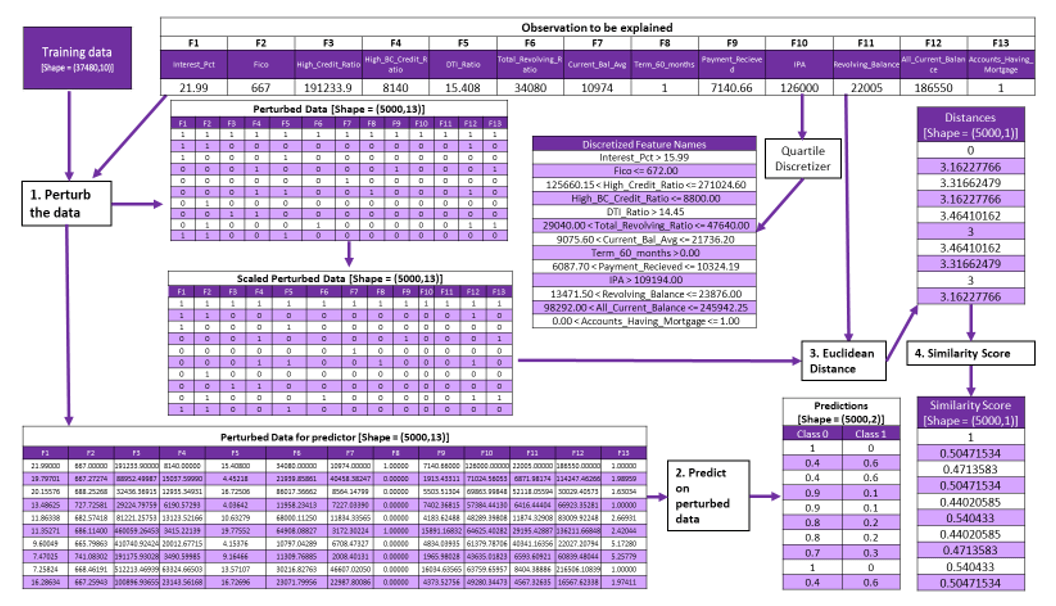
Step2: Feature selection and running the model
- Use the perturbed data for the selected features
- Build a weighted linear model using these inputs

- Output of the model provides the explanation for the prediction
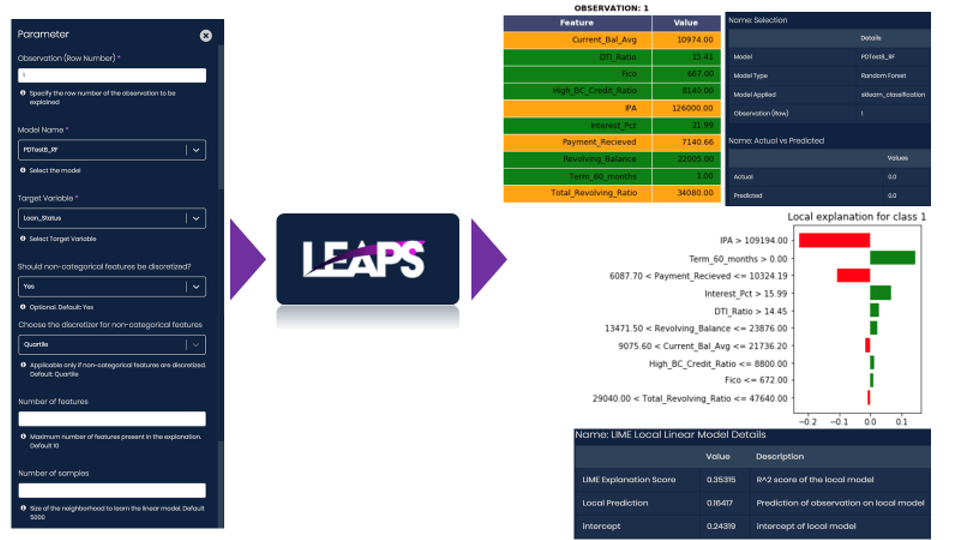
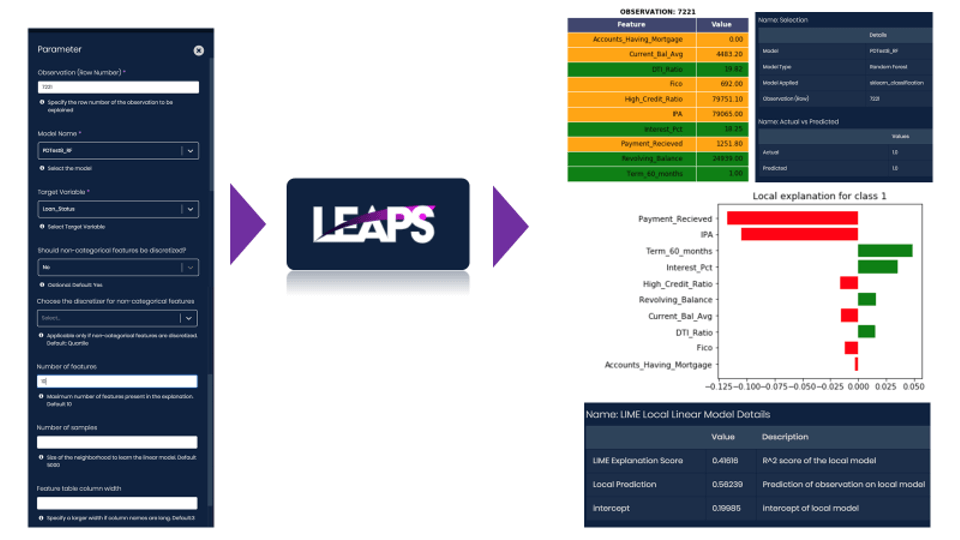
LIME on LEAPS
- LIME can be run on Analyttica TreasureHunt® LEAPS platform as a point & click function
- Hyperparameters for LIME can be tuned and experimented
- All the results from LIME are available on the output flyout for the user to analyse & interpret
CASE 2: Continuous variables are not discretized
Step 1: Creating the inputs required for the linear model
- Perturbing the data
- Predicting on the perturbed data
- Calculating the similarity score
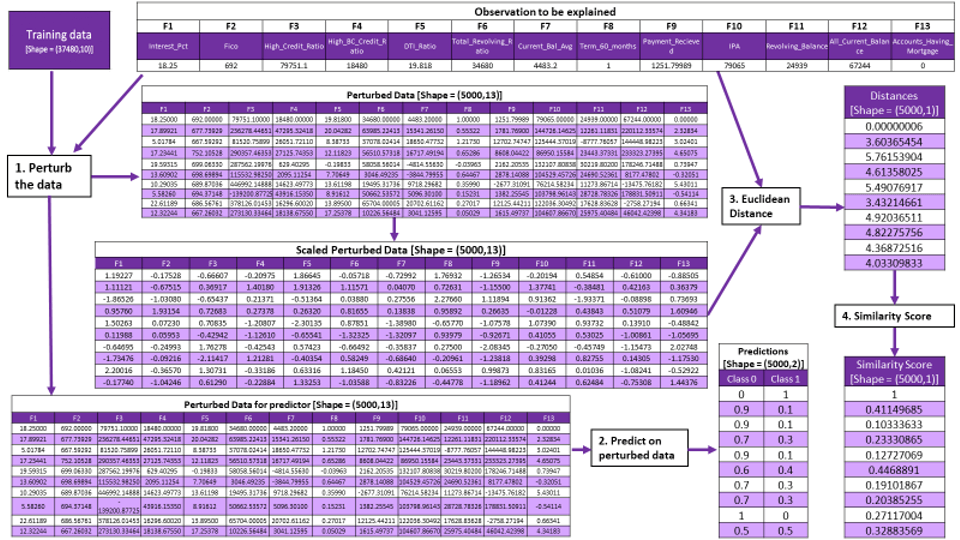
Step 2: Feature selection and running the model
- Use the perturbed data for the selected features
- Build a weighted linear model using these inputs
- Output of the model provides the explanation for the prediction
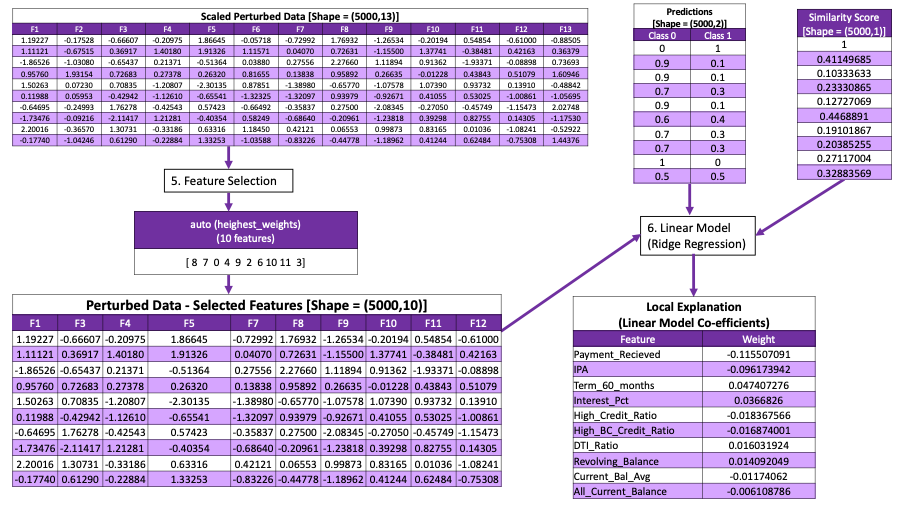
LIME on LEAPS
- Hyperparameters for LIME can be tuned. In this case it is explicity set that the continuous features should not be discretized.
- Notice the difference in the output features in case the continuous variables are not discretized.
Tuning Parameters in LIME
Tuning Parameters – Number of Features
- LIME creates the local linear model for the specified number of features
- The user can tune the number of features based on the complexity of the model and the simplicity of the explanation required.
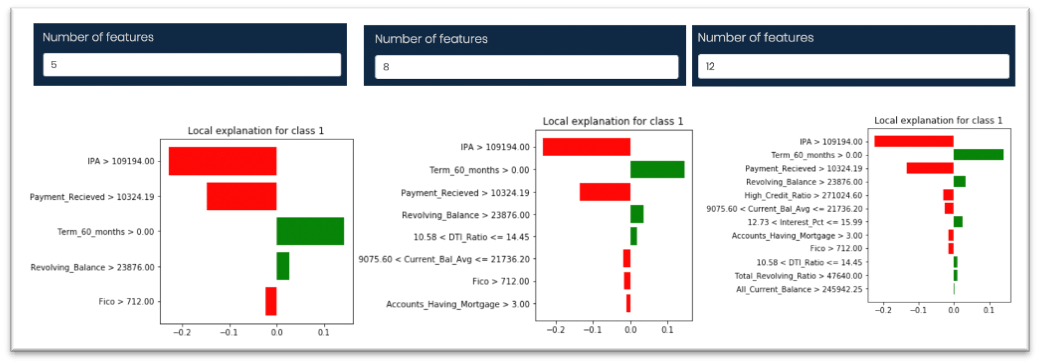
Tuning Parameters – Number of Samples
- LIME allows the user to tune the number of samples to be created for the perturbed data. (Default is 5000)
- In the below cases, the parameter is set to varying sample sizes of 1000, 5000 & 10000
- Notice that for this particular prediction, the top three features remain the same for all the sample sizes though their weights could differ.

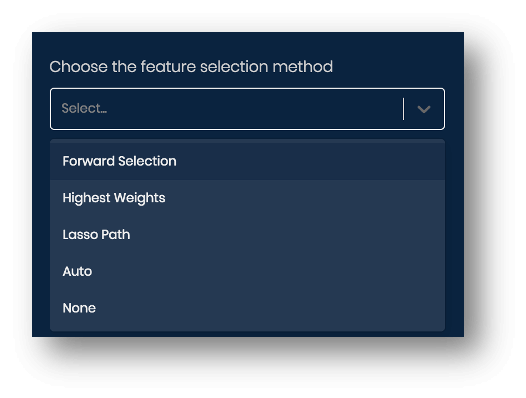
Tuning Parameters – Feature Selection
- LIME supports the following methods for feature selection
- Highest Weights – runs ridge regression on scaled data with all features and picks top num_features (m) with highest weights
- Forward Selection – iteratively adds features to the model and identifies the features that give the best score on the ridge model.
- Lasso Path – chooses features based on lasso regularization path
- none – considers all the features
- auto – if num_features (m) <= 6, forward selection else highest weights
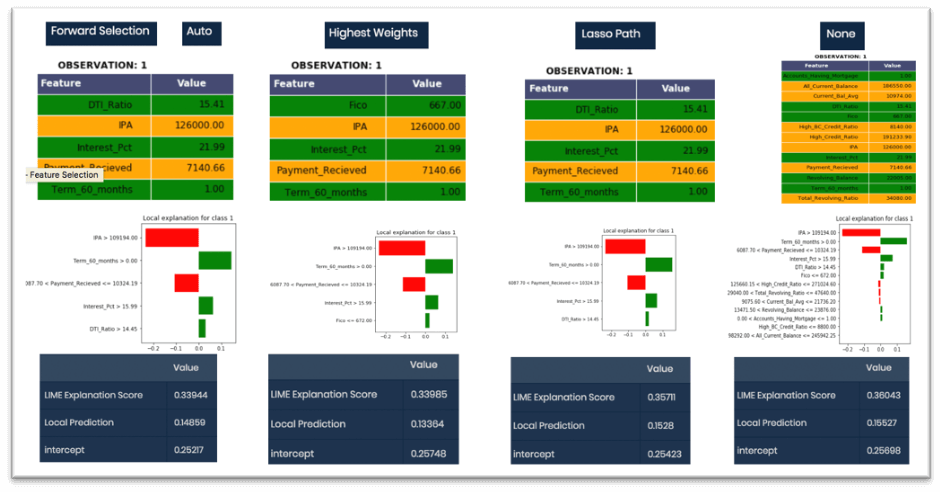
- Below visualization shows the behaviour of LIME on tuning for different feature selection method
- The top 3 features identified by all the methods is the same for this prediction
Tuning Parameters – Feature Selection
Tuning Parameters – Discretizing Features
- User can set the option to discretize non-categorical variables. In this case continuous
-
- variables are categorized
- The categorized continuous variables are in more human interpretable format. By default LIME categorizes continuous variables.
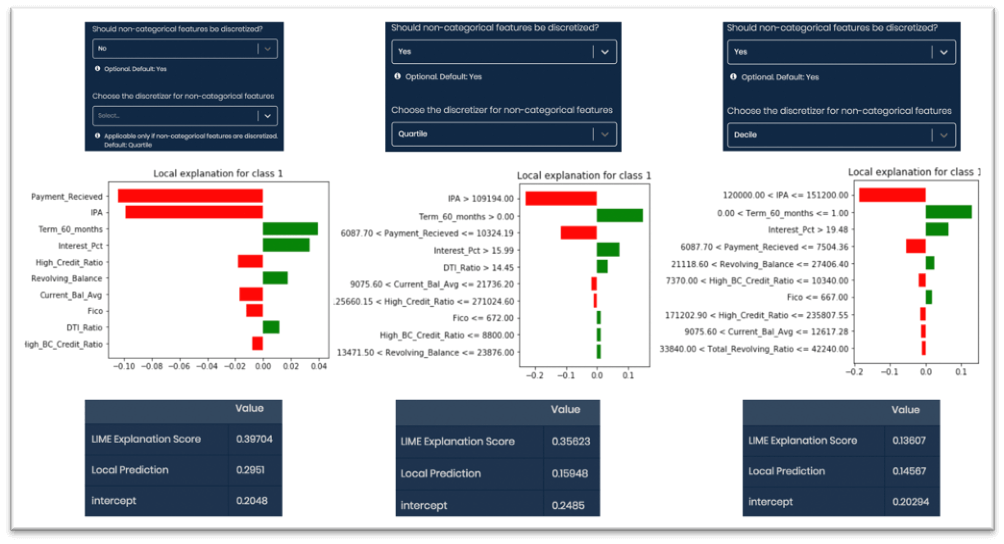
- Discretization for continuous variables could be of 3 types:
- Quartile (default),
- Decile
- Entropy
- Each variable is split to a discrete range based on the distribution in the training dataset
- In the below snapshots from LEAPS, the parameter was tuned to explain an observation first without discretizing continuous variable, then discretizing them with quartile discretizer and finally with the decile discretizer.
- Notice the difference in the feature names returned by LIME. The range varies based on the discretizer used.
Diving Deeper: How is the perturbed data created?
- LIME perturbs the input observation that has to be explained around its locality and creates a local data
- For categorical variables, random values are picked based on the possible category values and its frequency of occurrence in the training dataset
- For continuous variables, they are perturbed by sampling from a Normal (0,1) distribution and doing the inverse operation of mean-centering and scaling, according to the means and standard deviations in the training data
- First row in the perturbed data will always be the observation to be explained. Continuous variables in the perturbed data are scaled.
- Perturbed data have the values of 0 or 1 for categorical variables (data). 1 if category is same as the observation to be explained else 0.
Choosing the Linear Regression Model
- The only requirement for the local linear model is that it should work with weighted input and should be interpretable
- The weights here, are the similarity score calculated based on the distance of the perturbed observation to the original observation. Instances close to the original observation will have higher weights
- By default, Ridge Regression is used as the interpretable model
- LIME supports any sci-kit learn model as long as it has model_regressor.coef_ and ‘sample_weight’ as parameters to model_regressor.fit().
- The coefficients from the linear regression model is used in explaining the local behaviour of the observation
Where does LIME fail?
- As LIME creates its own sample data around the locality of the observation based on the gaussian distirbution, it is possible that some “unlikely” data points are created on which the model has learnt.
- If the decision boundary is too non-linear, the linear model might not explain it well (local fidelity may be high)
Going Global with LIME explanations
- The LIME paper explains another technique called the submodular pick (SP-LIME). This is to provide a global explanation of a model based on handful of explanations
- Run the explanation model on a diverse but representative set of instances to return a non-redundant explanation set that is a global representation of the model
- Algorithm
- Run the LIME model on all the instances of test data
- Extract the importance of each instance
- Maximise the coverage function by iteratively adding the instance with highest maximum coverage gain
- Return the representative non redundant explanation set
Conclusion
The applications of Explainable AI frameworks will continue to grow, enabling businesses to apply more robust and complex solutions in a ‘White-Box’ approach. XAI will not only enable Data Scientists and Analysts to refine and enhance their models, it will also enable them in bringing all stakeholders, be it internal business heads or external regulators, on the same page by being able to explain the complex data predictions in a closer to business format. Building trust and acceptance of such robust solutions.
LIME being model agnostic and providing explanations in human interpretable format has application across solutions and different industry domains, and as part of our solution thinking, we at Analyttica have been able to build and integrate XAI solutions in our patented platform Analyttica TreasureHunt® Precision. These solutions can be quickly contextualized to the business problem at hand and can be deployed at scale, to drive impact. We are already working with some of our key clients in the Healthcare and Financial Services domain to drive business impact at 4X the speed and 100% accuracy, by leveraging our proprietary solutions.
Sources/References